📮 nimzia [at] bu [dot] edu
🌕 Exploring mechanistic interpretability from a weight space perspective. If you're interested in this topic, let's connect!
Hello there!! I am a CS PhD student at Boston University, advised by Prof. Dr. Bryan Plummer. My research develops parameter-efficient adaptation methods for deep neural networks — spanning reparameterization and compression frameworks, evaluation protocols that surface failure modes in vision-language systems, and mechanistic interpretability through neuron-level analysis. Broadly, I work at the crossroads of modalities, with a strong emphasis on responsible AI and under-resourced communities.
- I was fortunate to be advised by Dr. Isaac Johnson and Dr. Martin Gerlach at the Wikimedia Research Team, where I built resources and pipelines for NLP research across the Wikimedia projects.
- I have published in multiple A* conferences and workshops, including ICLR, CVPR, Interspeech, NeuRIPS, EMNLP, and ACL. A partial list of my publications can be found here.
- I have a year of industry experience as a Machine Learning Engineer at Giga Tech Ltd. developing the National Syntactic TreeBank for Bangla, and as a Research Collaborator at Bengali.ai, building resources for low-resource languages.
- I also build open-source tools and datasets for the broader community — some projects are here.
Outside research and courseworks, I am interested in plants🪴, pottery ⚱️ and pop-culture 🖖 (See here ✨). Shoot me an email if you want to collaborate on a project, have a question, or just want to say hi~
news
| Mar 31, 2026 | Reviewed for ICML, ACL-ARR, and CVPR |
| Feb 21, 2026 | Second PhD paper accepted at CVPR'26 (Main Track)! |
| Jan 15, 2026 | New preprint on permanent knowledge erasure in LLMs is online! Read it on : [arXiv] |
| Jan 11, 2026 | TF-ing for a new graduate-level course on AI, Security and Entrepreneurship |
| Oct 25, 2025 | New Paper Alert: 2 papers accepted at IJCNLP'25! |
selected publications
- PEFT+CompressionCVPR
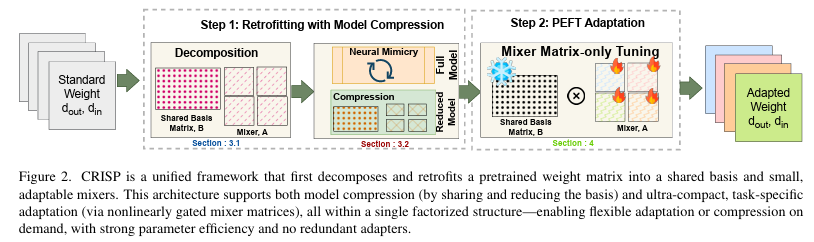 Decompose, Mix, Adapt: A Unified Framework for Parameter-Efficient Neural Network Recombination and Compression PDF
Decompose, Mix, Adapt: A Unified Framework for Parameter-Efficient Neural Network Recombination and Compression PDFAbstract:
Parameter Recombination (PR) methods aim to efficiently compose the weights of a neural network, and encompasses tasks like Parameter-Efficient FineTuning (PEFT) and Model Compression (MC), among others. Most methods typically focus on one application of PR, which can make composing them challenging. For example, when deploying a large model you may wish to compress the model and also quickly adapt to new settings. However, PEFT methods often can still contain millions of parameters. This may be small compared to the original model size, but can be problematic in resource constrained deployments like edge devices, where they take a larger portion of the compressed model’s parameters. To address this, we present Coefficient-gated weight Recombination by Interpolated Shared basis Projections (\method), a general approach that can address multiple PR tasks within the same framework, which can enable seamless integration. It accomplishes this by using a factorization process that decomposes pretrained weights into basis matrices and their component projections. Sharing these basis matrices across layers and adjusting its size enables us to perform MC, whereas the small size of the projection weights (fewer than 200 in some experiments) enables \method support PEFT. Experiments on ViT models show \method outperforms methods from prior work capable of dual-task applications by 4-5% while also outperforming the state-of-the-art in PEFT by 1.5% and PEFT+MC combinations by almost 1%.
- vlmunder review
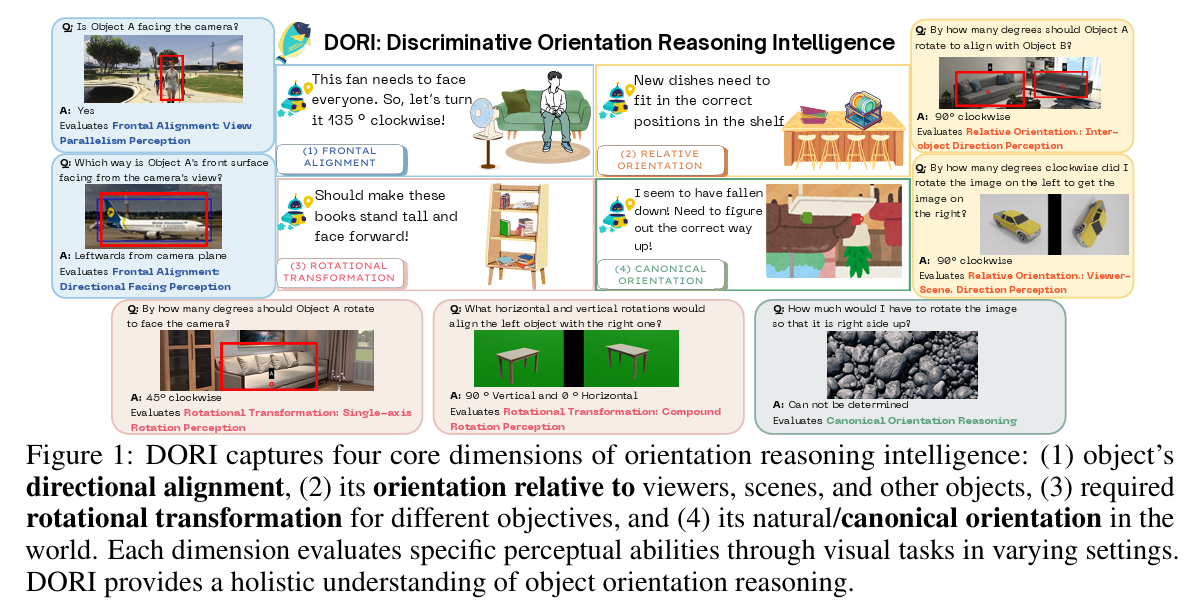 Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks PDF
Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks PDFAbstract:
Object orientation understanding represents a fundamental challenge in visual perception critical for applications like robotic manipulation and augmented reality. Current vision-language benchmarks fail to isolate this capability, often conflating it with positional relationships and general scene understanding. We introduce DORI (Discriminative Orientation Reasoning Intelligence), a comprehensive benchmark establishing object orientation perception as a primary evaluation target. DORI assesses four dimensions of orientation comprehension: frontal alignment, rotational transformations, relative directional relationships, and canonical orientation understanding. Through carefully curated tasks from 11 datasets spanning 67 object categories across synthetic and real-world scenarios, DORI provides insights on how multi-modal systems understand object orientations. Our evaluation of 15 state-of-the-art vision-language models reveals critical limitations: even the best models achieve only 54.2% accuracy on coarse tasks and 33.0% on granular orientation judgments, with performance deteriorating for tasks requiring reference frame shifts or compound rotations. These findings demonstrate the need for dedicated orientation representation mechanisms, as models show systematic inability to perform precise angular estimations, track orientation changes across viewpoints, and understand compound rotations - suggesting limitations in their internal 3D spatial representations. As the first diagnostic framework specifically designed for orientation awareness in multimodal systems, DORI offers implications for improving robotic control, 3D scene reconstruction, and human-AI interaction in physical environments.
- mechinterpunder review
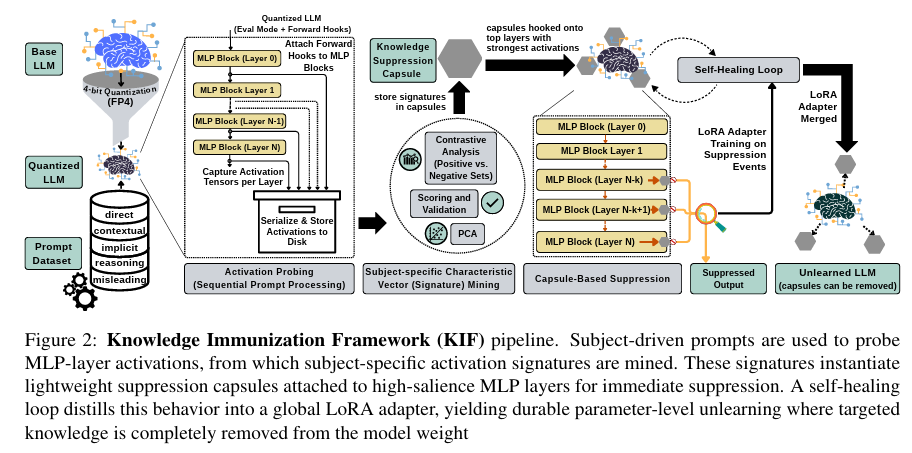 Representation-Aware Unlearning via Activation Signatures: From Suppression to Knowledge-Signature Erasure PDF
Representation-Aware Unlearning via Activation Signatures: From Suppression to Knowledge-Signature Erasure PDFAbstract:
Selective knowledge erasure from LLMs is critical for GDPR compliance and model safety, yet current unlearning methods conflate behavioral suppression with true knowledge removal, allowing latent capabilities to persist beneath surface-level refusals. In this work, we address this challenge by introducing Knowledge Immunization Framework (KIF), a representation-aware architecture that distinguishes genuine erasure from obfuscation by targeting internal activation signatures rather than surface outputs. Our approach combines dynamic suppression of subject-specific representations with parameter-efficient adaptation, enabling durable unlearning without full model retraining. KIF achieves near-oracle erasure (FQ approx 0.99 vs. 1.00) while preserving utility at oracle levels (MU = 0.62), effectively breaking the stability-erasure tradeoff that has constrained all prior work. We evaluate both standard foundation models (Llama and Mistral) and reasoning-prior models (Qwen and DeepSeek) across 3B to 14B parameters. Our observation shows that standard models exhibit scale-independent true erasure (<3% utility drift), while reasoning-prior models reveal fundamental architectural divergence. Our comprehensive dual-metric evaluation protocol, combining surface-level leakage with latent trace persistence, operationalizes the obfuscation - erasure distinction and enables the first systematic diagnosis of mechanism-level forgetting behavior across model families and scales.
-
Abstract:
Incremental learning aims to adapt to new sets of categories over time with minimal computational overhead. Prior work often addresses this task by training efficient task-specific adaptors that modify frozen layer weights or features to capture relevant information without affecting predictions on previously learned categories. While these adaptors are generally more efficient than finetuning the entire network, they still require tens to hundreds of thousands of task-specific trainable parameters even for relatively small networks, making it challenging to operate on resource-constrained environments with high communication costs like edge devices or mobile phones. Thus, we propose Reparameterized, Compact weight Adaptation for Sequential Tasks (RECAST), a novel method that dramatically reduces task-specific trainable parameters to fewer than 50 - several orders of magnitude less than competing methods like LoRA. RECAST accomplishes this efficiency by learning to decompose layer weights into a soft parameter-sharing framework consisting of shared weight templates and very few module-specific scaling factors or coefficients. This soft parameter-sharing framework allows for effective task-wise reparameterization by tuning only these coefficients while keeping templates frozen.A key innovation of RECAST is the novel weight reconstruction pipeline called Neural Mimicry, which eliminates the need for pretraining from scratch. This allows for high-fidelity emulation of existing pretrained weights within our framework and provides quick adaptability to any model scale and architecture
- nlpAACL-IJCNLP
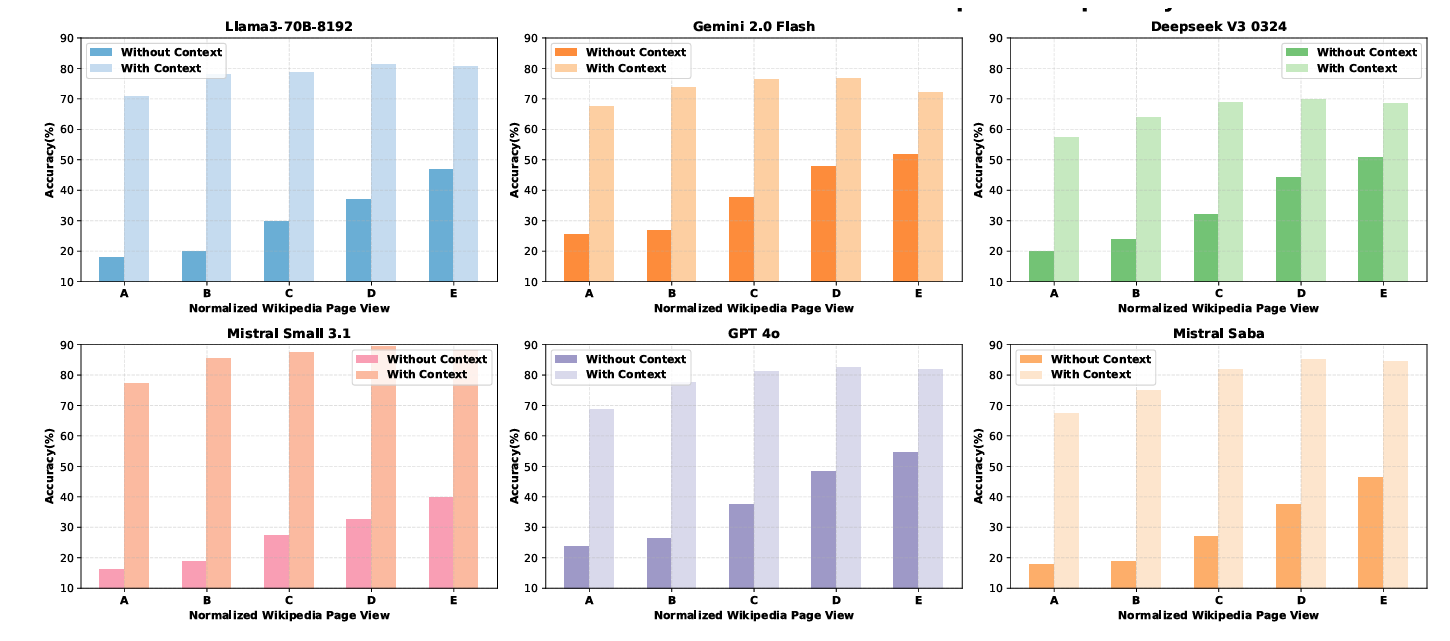 From Facts to Folklore: Evaluating Large Language Models on Bengali Cultural Knowledge PDF
From Facts to Folklore: Evaluating Large Language Models on Bengali Cultural Knowledge PDFAbstract:
Recent progress in NLP research has demonstrated remarkable capabilities of large language models (LLMs) across a wide range of tasks. While recent multilingual benchmarks have advanced cultural evaluation for LLMs, critical gaps remain in capturing the nuances of low-resource cultures. Our work addresses these limitations through a Bengali Language Cultural Knowledge (BLanCK) dataset including folk traditions, culinary arts, and regional dialects. Our investigation of several multilingual language models shows that while these models perform well in non-cultural categories, they struggle significantly with cultural knowledge and performance improves substantially across all models when context is provided, emphasizing context-aware architectures and culturally curated training data.
- speechAACL-IJCNLP
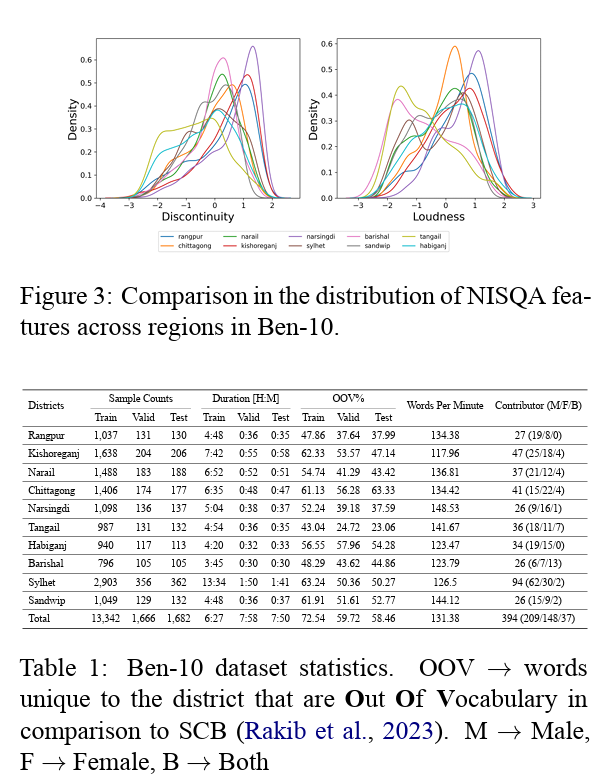 Are ASR foundation models generalized enough to capture features of regional dialects for low-resource languages? PDF
Are ASR foundation models generalized enough to capture features of regional dialects for low-resource languages? PDFAbstract:
Conventional research on speech recognition modeling relies on the canonical form for most low-resource languages while automatic speech recognition (ASR) for regional dialects is treated as a fine-tuning task. To investigate the effects of dialectal variations on ASR we develop a 78-hour annotated Bengali Speech-to-Text (STT) corpus named Ben-10. Investigation from linguistic and data-driven perspectives shows that speech foundation models struggle heavily in regional dialect ASR, both in zero-shot and fine-tuned settings. We observe that all deep learning methods struggle to model speech data under dialectal variations, but dialect specific model training alleviates the issue. Our dataset also serves as a out-of-distribution (OOD) resource for ASR modeling under constrained resources in ASR algorithms. The dataset and code developed for this project are publicly available.
-
Abstract:
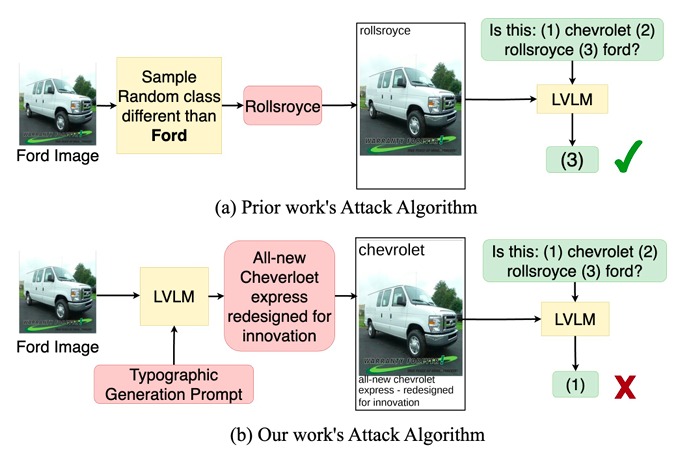
Typographic attacks, adding misleading text to images, can deceive vision-language models (LVLMs). The susceptibility of recent large LVLMs like GPT4-V to such attacks is understudied, raising concerns about amplified misinformation in personal assistant applications. Previous attacks use simple strategies, such as random misleading words, which don’t fully exploit LVLMs’ language reasoning abilities. We introduce an experimental setup for testing typographic attacks on LVLMs and propose two novel self-generated attacks: (1) Class-based attacks, where the model identifies a similar class to deceive itself, and (2) Reasoned attacks, where an advanced LVLM suggests an attack combining a deceiving class and description. Our experiments show these attacks significantly reduce classification performance by up to 60% and are effective across different models, including InstructBLIP and MiniGPT4. Code: https://github.com/mqraitem/Self-Gen-Typo-Attack
- speechINTERSPEECH
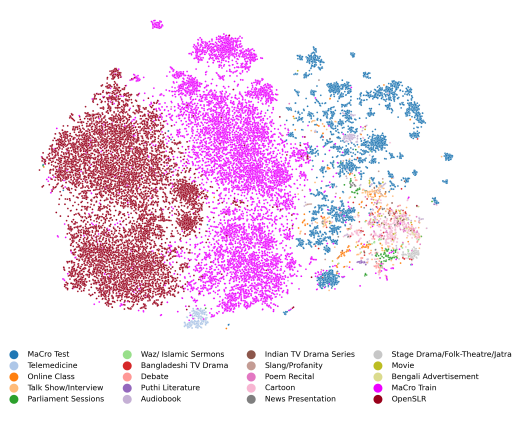 OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking PDF
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking PDFAbstract:
We present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spoken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are delivered with a tonality that is significantly different from regular speech. Our training dataset is collected via massively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from native Bengali speakers from South Asia. Our test dataset comprises 23.03 hours of speech collected and manually annotated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest publicly available speech dataset, as well as the first out-of-distribution ASR benchmarking dataset for Bengali.