publications
2026
- PEFT+CompressionCVPR
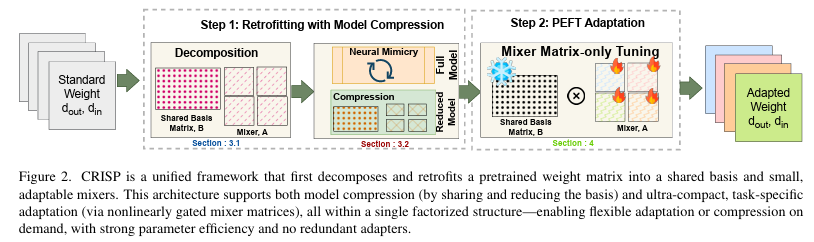 Decompose, Mix, Adapt: A Unified Framework for Parameter-Efficient Neural Network Recombination and Compression
Decompose, Mix, Adapt: A Unified Framework for Parameter-Efficient Neural Network Recombination and CompressionParameter Recombination (PR) methods aim to efficiently compose the weights of a neural network, and encompasses tasks like Parameter-Efficient FineTuning (PEFT) and Model Compression (MC), among others. Most methods typically focus on one application of PR, which can make composing them challenging. For example, when deploying a large model you may wish to compress the model and also quickly adapt to new settings. However, PEFT methods often can still contain millions of parameters. This may be small compared to the original model size, but can be problematic in resource constrained deployments like edge devices, where they take a larger portion of the compressed model’s parameters. To address this, we present Coefficient-gated weight Recombination by Interpolated Shared basis Projections (\method), a general approach that can address multiple PR tasks within the same framework, which can enable seamless integration. It accomplishes this by using a factorization process that decomposes pretrained weights into basis matrices and their component projections. Sharing these basis matrices across layers and adjusting its size enables us to perform MC, whereas the small size of the projection weights (fewer than 200 in some experiments) enables \method support PEFT. Experiments on ViT models show \method outperforms methods from prior work capable of dual-task applications by 4-5% while also outperforming the state-of-the-art in PEFT by 1.5% and PEFT+MC combinations by almost 1%.
2025
- vlmunder review
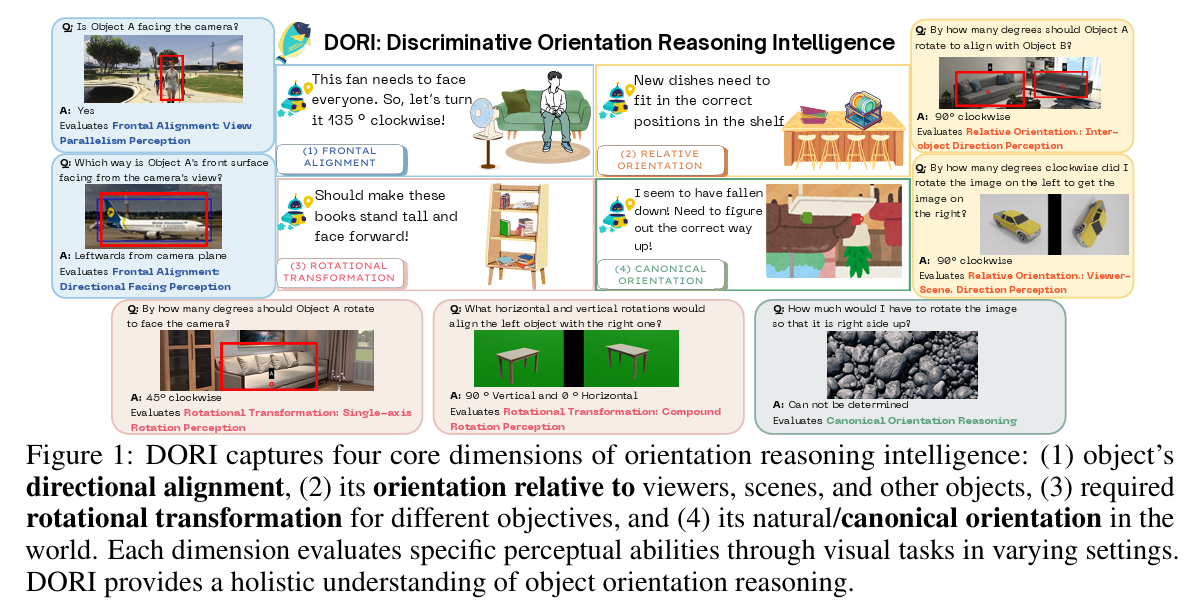 Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks
Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception TasksObject orientation understanding represents a fundamental challenge in visual perception critical for applications like robotic manipulation and augmented reality. Current vision-language benchmarks fail to isolate this capability, often conflating it with positional relationships and general scene understanding. We introduce DORI (Discriminative Orientation Reasoning Intelligence), a comprehensive benchmark establishing object orientation perception as a primary evaluation target. DORI assesses four dimensions of orientation comprehension: frontal alignment, rotational transformations, relative directional relationships, and canonical orientation understanding. Through carefully curated tasks from 11 datasets spanning 67 object categories across synthetic and real-world scenarios, DORI provides insights on how multi-modal systems understand object orientations. Our evaluation of 15 state-of-the-art vision-language models reveals critical limitations: even the best models achieve only 54.2% accuracy on coarse tasks and 33.0% on granular orientation judgments, with performance deteriorating for tasks requiring reference frame shifts or compound rotations. These findings demonstrate the need for dedicated orientation representation mechanisms, as models show systematic inability to perform precise angular estimations, track orientation changes across viewpoints, and understand compound rotations - suggesting limitations in their internal 3D spatial representations. As the first diagnostic framework specifically designed for orientation awareness in multimodal systems, DORI offers implications for improving robotic control, 3D scene reconstruction, and human-AI interaction in physical environments.
- mechinterpunder review
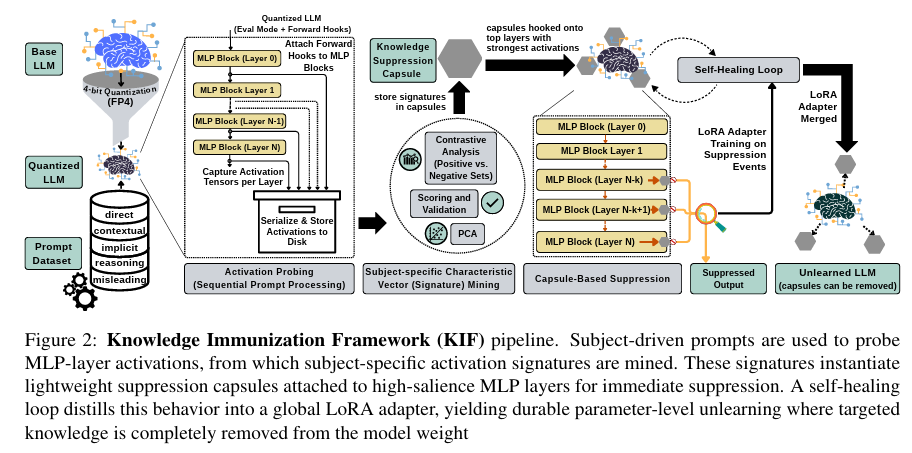 Representation-Aware Unlearning via Activation Signatures: From Suppression to Knowledge-Signature Erasure
Representation-Aware Unlearning via Activation Signatures: From Suppression to Knowledge-Signature ErasureSelective knowledge erasure from LLMs is critical for GDPR compliance and model safety, yet current unlearning methods conflate behavioral suppression with true knowledge removal, allowing latent capabilities to persist beneath surface-level refusals. In this work, we address this challenge by introducing Knowledge Immunization Framework (KIF), a representation-aware architecture that distinguishes genuine erasure from obfuscation by targeting internal activation signatures rather than surface outputs. Our approach combines dynamic suppression of subject-specific representations with parameter-efficient adaptation, enabling durable unlearning without full model retraining. KIF achieves near-oracle erasure (FQ approx 0.99 vs. 1.00) while preserving utility at oracle levels (MU = 0.62), effectively breaking the stability-erasure tradeoff that has constrained all prior work. We evaluate both standard foundation models (Llama and Mistral) and reasoning-prior models (Qwen and DeepSeek) across 3B to 14B parameters. Our observation shows that standard models exhibit scale-independent true erasure (<3% utility drift), while reasoning-prior models reveal fundamental architectural divergence. Our comprehensive dual-metric evaluation protocol, combining surface-level leakage with latent trace persistence, operationalizes the obfuscation - erasure distinction and enables the first systematic diagnosis of mechanism-level forgetting behavior across model families and scales.
- PEFTICLR
 RECAST: Reparameterized, Compact weight Adaptation for Sequential Tasks
RECAST: Reparameterized, Compact weight Adaptation for Sequential TasksIncremental learning aims to adapt to new sets of categories over time with minimal computational overhead. Prior work often addresses this task by training efficient task-specific adaptors that modify frozen layer weights or features to capture relevant information without affecting predictions on previously learned categories. While these adaptors are generally more efficient than finetuning the entire network, they still require tens to hundreds of thousands of task-specific trainable parameters even for relatively small networks, making it challenging to operate on resource-constrained environments with high communication costs like edge devices or mobile phones. Thus, we propose Reparameterized, Compact weight Adaptation for Sequential Tasks (RECAST), a novel method that dramatically reduces task-specific trainable parameters to fewer than 50 - several orders of magnitude less than competing methods like LoRA. RECAST accomplishes this efficiency by learning to decompose layer weights into a soft parameter-sharing framework consisting of shared weight templates and very few module-specific scaling factors or coefficients. This soft parameter-sharing framework allows for effective task-wise reparameterization by tuning only these coefficients while keeping templates frozen.A key innovation of RECAST is the novel weight reconstruction pipeline called Neural Mimicry, which eliminates the need for pretraining from scratch. This allows for high-fidelity emulation of existing pretrained weights within our framework and provides quick adaptability to any model scale and architecture
- nlpAACL-IJCNLP
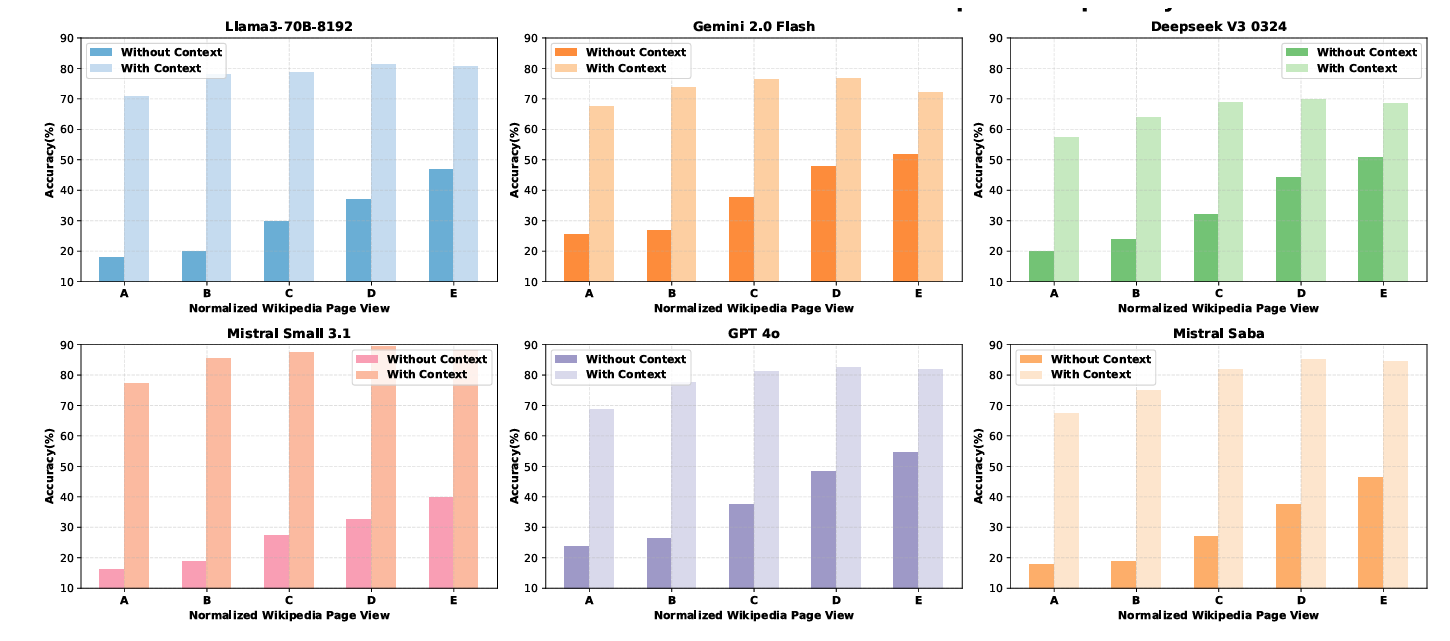 From Facts to Folklore: Evaluating Large Language Models on Bengali Cultural Knowledge
From Facts to Folklore: Evaluating Large Language Models on Bengali Cultural KnowledgeRecent progress in NLP research has demonstrated remarkable capabilities of large language models (LLMs) across a wide range of tasks. While recent multilingual benchmarks have advanced cultural evaluation for LLMs, critical gaps remain in capturing the nuances of low-resource cultures. Our work addresses these limitations through a Bengali Language Cultural Knowledge (BLanCK) dataset including folk traditions, culinary arts, and regional dialects. Our investigation of several multilingual language models shows that while these models perform well in non-cultural categories, they struggle significantly with cultural knowledge and performance improves substantially across all models when context is provided, emphasizing context-aware architectures and culturally curated training data.
- speechAACL-IJCNLP
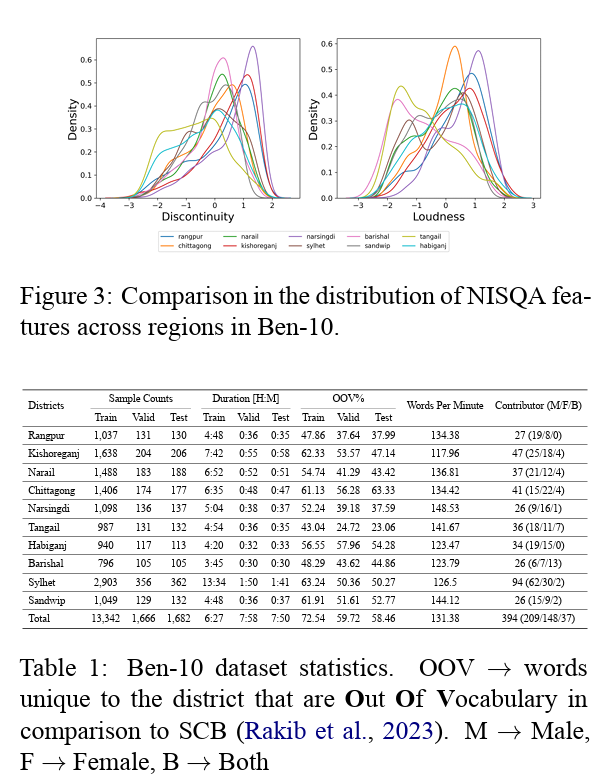 Are ASR foundation models generalized enough to capture features of regional dialects for low-resource languages?
Are ASR foundation models generalized enough to capture features of regional dialects for low-resource languages?Conventional research on speech recognition modeling relies on the canonical form for most low-resource languages while automatic speech recognition (ASR) for regional dialects is treated as a fine-tuning task. To investigate the effects of dialectal variations on ASR we develop a 78-hour annotated Bengali Speech-to-Text (STT) corpus named Ben-10. Investigation from linguistic and data-driven perspectives shows that speech foundation models struggle heavily in regional dialect ASR, both in zero-shot and fine-tuned settings. We observe that all deep learning methods struggle to model speech data under dialectal variations, but dialect specific model training alleviates the issue. Our dataset also serves as a out-of-distribution (OOD) resource for ASR modeling under constrained resources in ASR algorithms. The dataset and code developed for this project are publicly available.
2024
- visionNeuRIPS
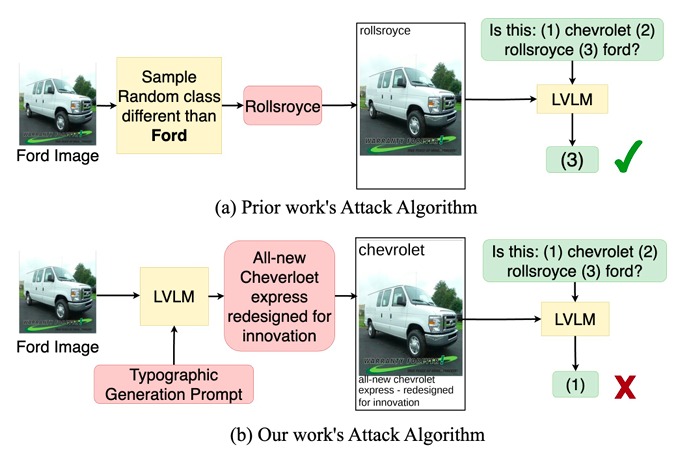 Vision-LLMs Can Fool Themselves with Self-Generated Typographic Attacks
Vision-LLMs Can Fool Themselves with Self-Generated Typographic AttacksTypographic attacks, adding misleading text to images, can deceive vision-language models (LVLMs). The susceptibility of recent large LVLMs like GPT4-V to such attacks is understudied, raising concerns about amplified misinformation in personal assistant applications. Previous attacks use simple strategies, such as random misleading words, which don’t fully exploit LVLMs’ language reasoning abilities. We introduce an experimental setup for testing typographic attacks on LVLMs and propose two novel self-generated attacks: (1) Class-based attacks, where the model identifies a similar class to deceive itself, and (2) Reasoned attacks, where an advanced LVLM suggests an attack combining a deceiving class and description. Our experiments show these attacks significantly reduce classification performance by up to 60% and are effective across different models, including InstructBLIP and MiniGPT4. Code: https://github.com/mqraitem/Self-Gen-Typo-Attack
2023
- speechINTERSPEECH
 OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution BenchmarkingWe present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spoken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are delivered with a tonality that is significantly different from regular speech. Our training dataset is collected via massively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from native Bengali speakers from South Asia. Our test dataset comprises 23.03 hours of speech collected and manually annotated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest publicly available speech dataset, as well as the first out-of-distribution ASR benchmarking dataset for Bengali.
2022
- visionCVPR
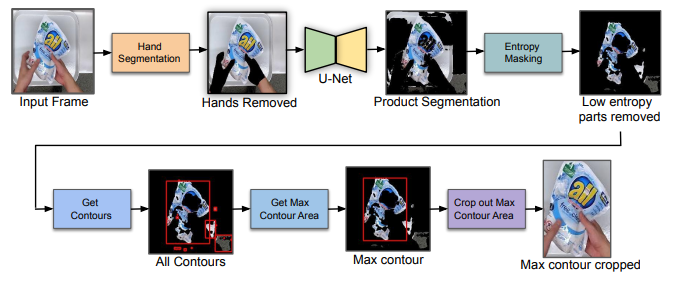 Vista: vision transformer enhanced by u-net and image colorfulness frame filtration for automatic retail checkout
Vista: vision transformer enhanced by u-net and image colorfulness frame filtration for automatic retail checkoutMulti-class product counting and recognition identifies product items from images or videos for automated retail checkout. The task is challenging due to the real-world scenario of occlusions where product items overlap, fast movement in conveyor belt, large similarity in overall appearance of the items being scanned, novel products, the negative impact of misidentifying items. Further there is a domain bias between training and test sets, specifically the provided training dataset consists of synthetic images and the test set videos consist of foreign objects such as hands and tray. To address these aforementioned issues, we propose to segment and classify individual frames from a video sequence. The segmentation method consists of a unified single product item-and hand-segmentation followed by entropy masking to address the domain bias problem. The multi-class classification method is based on Vision Transformers (ViT). To identify the frames with target objects, we utilize several image processing methods and propose a custom metric to discard frames not having any product items. Combining all these mechanisms, our best system achieves 3rd place in the AI City Challenge 2022 Track 4 with F1 score of 0.4545.
- nlpSemEval
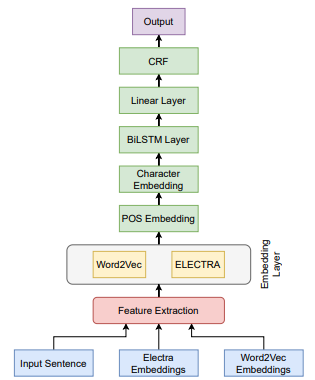 On leveraging data augmentation and ensemble to recognize complex named entities in bangla
On leveraging data augmentation and ensemble to recognize complex named entities in banglaMany areas, such as the biological and healthcare domain, artistic works, and organization names, have nested, overlapping, discontinuous entity mentions that may even be syntactically or semantically ambiguous in practice. Traditional sequence tagging algorithms are unable to recognize these complex mentions because they may violate the assumptions upon which sequence tagging schemes are founded. In this paper, we describe our contribution to SemEval 2022 Task 11 on identifying such complex Named Entities. We have leveraged the ensemble of multiple ELECTRA-based models that were exclusively pretrained on the Bangla language with the performance of ELECTRA-based models pretrained on English to achieve competitive performance on the Track-11. Besides providing a system description, we will also present the outcomes of our experiments on architectural decisions, dataset augmentations, and post-competition findings.
- nlpKDD-Health
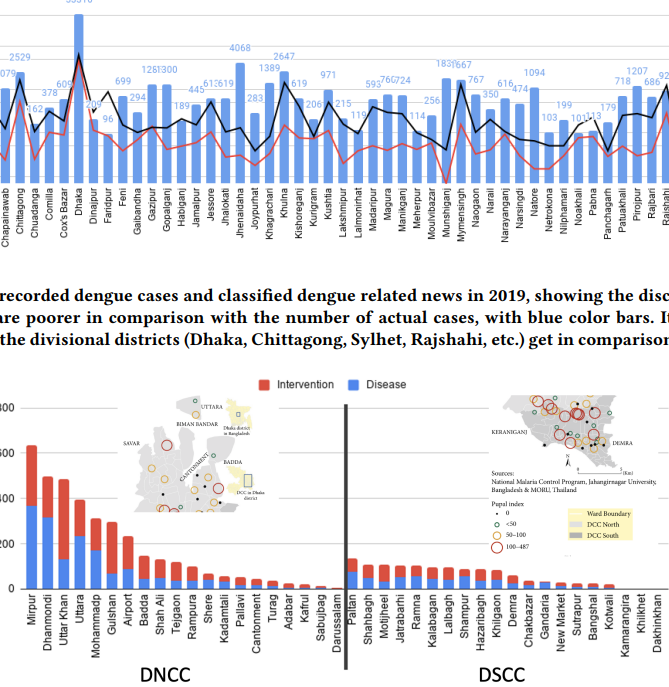 Exploring the Scope and Potential of Local Newspaper-based Dengue Surveillance in Bangladesh
Exploring the Scope and Potential of Local Newspaper-based Dengue Surveillance in Bangladesh
2021
- nlpFLAIRS
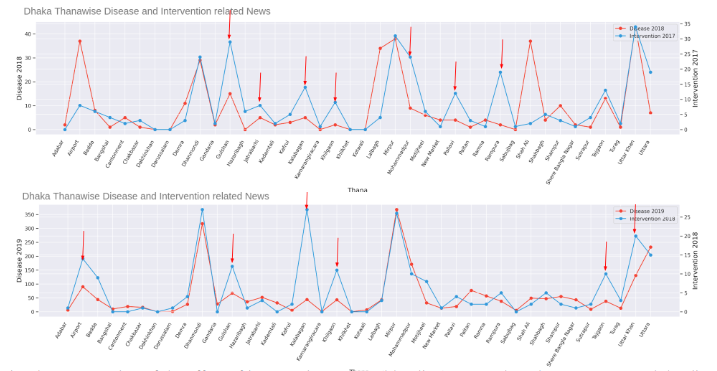 Observing the unobserved: a newspaper based dengue surveillance system for the low-income regions of bangladesh
Observing the unobserved: a newspaper based dengue surveillance system for the low-income regions of bangladeshDengue is one of the emerging diseases of this century, which established itself as both endemic and epidemic-particularly in the tropical and subtropical-regions. Because of its high morbidity and mortality rates, Dengue is a significant economic and health burden for middle to lower-income countries. The lack of a stable, cost-effective, and suitable surveillance system has made the identification of dengue zones and designing potential control programs very challenging. As a result, it is not feasible to assess the effect of the intervention actions properly. Therefore, most of the prevention and mitigation efforts by the associated health officials are failing. In this work, we chose Bangladesh, a developing country from the South-East Asia region with its occasional history of dengue outbreaks and with a high out-of-pocket medical expenditure, as a use case. We use some well known data-mining techniques on the local newspapers, written in Bengali, to unearth valuable insights and develop a dengue news surveillance system. We categorize dengue-news and detect the spatio-temporal trends among crucial variables. Our technique provides an f-score of 91.45% and very closely follows the ground truth of reported cases. Additionally, we identify the under-reported regions of the country effectively while establishing a meaningful relationship between complex socio-economic factors and reporting of dengue.
- bioBriefings in Bioinformatics
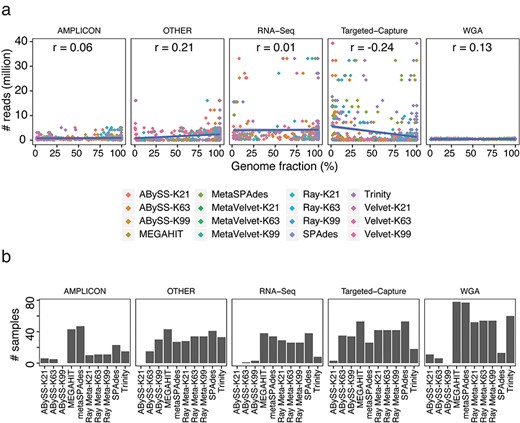 Choice of assemblers has a critical impact on de novo assembly of sars-cov-2 genome and characterizing variants
Choice of assemblers has a critical impact on de novo assembly of sars-cov-2 genome and characterizing variants
2020
-
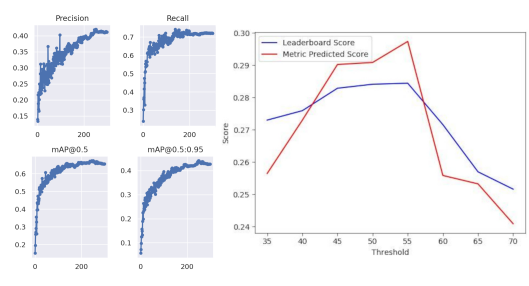 Team Passphrase: Dhaka AI Vehicle Detection Challenge 4th place Submission
Team Passphrase: Dhaka AI Vehicle Detection Challenge 4th place SubmissionTraffic detection comes with many different challenges depending on the specific characteristics of the problem domain. Dhaka traffic has its own distinctive elements and dynamics. To design an effective object detection model that captures the essence of dhaka traffic, careful model optimization and data engineering is needed. So, we focus on developing a robust pipeline using an ensemble of existing SOTA models, to ensure improved generalization and less dependency on model complexity.